33. ПО веб-сервера. Действия сервера. Способы увеличения производительности серверов. Популярное ПО для веб-серверов (Apache и т.д.)
Когда пользователь вводит URL или щелкает на гиперссылке, браузер производит структурный анализ URL и интерпретирует часть, заключенную между http:// и следующей косой чертой, как имя DNS, которое следует искать. Вооружившись IP-адресом сервера, браузер устанавливает TCP-соединение с портом 80 этого сервера. После этого отсылается команда, содержащая оставшуюся часть URL, в которой указывается имя файла на сервере. Сервер возвращает браузеру запрашиваемый файл для отображения.
В первом приближении веб-сервер напоминает сервер, представленный в листинге 4.2. Этому серверу, как и настоящему веб-серверу, передается имя файла, который следует найти и отправить. В обоих случаях в основном цикле сервер выполняет следующие действия:
1) Принимает входящее TCP-соединение от клиента (браузера).
2) Получает имя запрашиваемого файла.
3) Получает файл (с диска).
4) Возвращает файл клиенту.
5) Разрывает TCP-соединение.
Современные веб-серверы обладают более широкими возможностями, однако существенными в их работе являются именно перечисленные шаги.
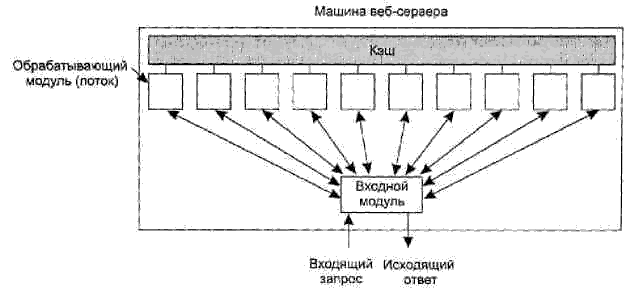
Проблема данного подхода заключается в том, что каждый запрос требует обращения к диску для получения файла. В результате число обращений к веб-серверу за секунду ограничено максимальной скоростью обращений к диску. Среднее время доступа к высокоскоростному диску типа SCSI составляет около 5 мс, то есть сервер может обрабатывать не более 200 обращений в секунду. Это число даже меньше, если часто запрашиваются большие файлы. Для крупных веб-сайтов это слишком мало. Очевидным способом решения проблемы является кэширование в памяти последних запрошенных файлов. Прежде чем обратиться за файлом к диску, сервер проверяет содержимое кэша. Если файл обнаруживается в кэше, его можно сразу выдать клиенту, не обращаясь к диску. Несмотря на то, что для эффективного кэширования требуются большие объемы памяти и некоторое дополнительное время на проверку кэша и управление его содержимым, суммарный выигрыш во времени почти всегда оправдывает эти накладные расходы и стоимость. Следующим шагом, направленным на повышение производительности, является создание многопоточных серверов. Одна из реализаций подразумевает, что сервер состоит из входного модуля, принимающего все входящие запросы, и k обрабатывающих модулей (рис. 5.5). Все k + 1 потоков принадлежат одному и тому же процессу, поэтому у обрабатывающих модулей есть доступ к кэшу в адресном пространстве процесса. Когда приходит запрос, входящий модуль принимает его и создает краткую запись с его описанием. Затем запись передается одному из обрабатывающих модулей. Другая возможная реализация подразумевает отсутствие входного модуля; все обрабатывающие модули пытаются получить запросы, однако здесь требуется блокирующий протокол, помогающий избежать конфликтов.
Рисунок 5.5 — Многопоточный веб-сервер с входным и обрабатывающими модулями
Обрабатывающий модуль вначале проверяет кэш на предмет нахождения там нужных файлов. Если они там действительно есть, он обновляет запись, включая в нее указатель на файл. Если искомого файла в кэше нет, обрабатывающий модуль обращается к диску и считывает файл в кэш (при этом, возможно, затирая некоторые хранящиеся там файлы, чтобы освободить место). Считанный с диска файл попадает в кэш и отсылается клиенту. Преимущество такой схемы заключается в том, что пока один или несколько обрабатывающих модулей заблокированы в ожидании окончания дисковой операции (при этом такие модули не потребляют мощности центрального процессора), другие модули могут активно обрабатывать захваченные ими запросы. Разумеется, реального повышения производительности за счет многопоточной схемы можно достичь, только если установить несколько дисков, чтобы в каждый момент времени можно было обращаться более чем к одному диску. Имея k обрабатывающих модулей и k дисков, производительность можно повысить в k раз по сравнению с однопоточным сервером и одним диском. Теоретически, однопоточный сервер с k дисками тоже должен давать прирост производительности в k раз, однако программирование и администрирование такой схемы оказывается очень сложным, так как в этом случае невозможно использование обычных блокирующих системных вызовов READ для чтения с диска. Многопоточные серверы такого ограничения не имеют, поскольку READ будет блокировать только тот поток, который осуществил системный вызов, а не весь процесс. Современные веб-серверы выполняют гораздо больше функций, чем просто прием имен файлов и отправка файлов. На самом деле, реальная обработка каждого запроса может оказаться довольно сложной. По этой причине на многих серверах каждый обрабатывающий модуль выполняет серии действий. Входной модуль передает каждый входящий запрос первому доступному модулю, который обрабатывает его путем выполнения некоторого подмножества указанных далее шагов в зависимости от того, что именно требуется для данного запроса:
1) вычисление имени запрашиваемой веб-страницы;
2) регистрация клиента;
3) осуществление контроля доступа для клиента;
4) осуществление контроля доступа для веб-страницы;
5) проверка кэша;
6) получение запрошенной страницы с диска;
7) определение типа MIME для включения этой информации в ответ клиенту;
8) аккуратное выполнение различных дополнительных задач;
9) возвращение ответа клиенту;
10) добавление записи в журнал активности сервера.
Шаг 1 необходим, потому что входящий запрос может и не содержать реального имени файла в виде строкового литерала. Шаг 2 состоит в проверке идентификационных данных клиента. Это нужно для отображения страниц, недоступных для широкой публики. Шаг 3 проверяет наличие каких-либо ограничений, накладываемых на данного клиента и его местоположение. На шаге 4 проверяются ограничения на доступ к запрашиваемой странице. Если определенный файл (например, .htaccess) присутствует в том же каталоге, что и нужная страница, он может ограничивать доступ к файлу. Шаги 5 и 6 включают в себя получение страницы. Во время выполнения шага 6 должна быть обеспечена возможность одновременного чтения с нескольких дисков. Шаг 7 связан с определением типа MIME, исходя из расширения файла, первых нескольких байтов, конфигурационного файла или каких-то иных источников. Шаг 8 предназначен для различных задач, таких как построение профиля пользователя, сбор статистики и т.д. На шаге 9 наконец отсылается результат, что фиксируется в журнале активности сервера на шаге 10. Последний шаг требуется для нужд администрирования. Из подобных журналов можно впоследствии узнать ценную информацию о поведении пользователей — например, о том, в каком порядке люди посещают страницы на сайте. Если приходит слишком много запросов в секунду, центральный процессор может перестать справляться с их обработкой вне зависимости от того, сколько дисков параллельно работают на сервере. Решается эта проблема установкой на сервере нескольких узлов (компьютеров). Их полезно укомплектовывать реплицированными (содержащими одинаковую информацию) дисками во избежание ситуации, когда узким местом становится дисковый накопитель. В результате возникает многомашинная система, организованная в виде серверной фермы (рис. 5.6). Входной модуль по-прежнему принимает входящие запросы, однако распределяет их на сей раз не между потоками, а между центральными процессорами, снижая тем самым нагрузку на каждый компьютер. Отдельные машины сами по себе могут быть многопотоковыми с конвейеризацией, как и в рассматриваемом ранее случае.
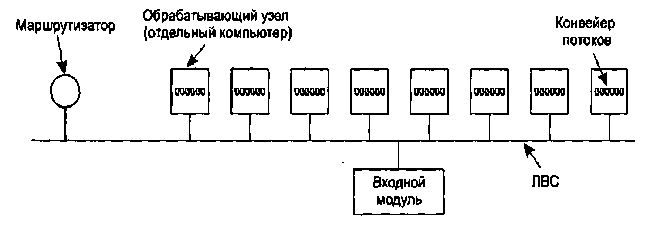
Рисунок 5.6 — Серверная ферма
Одна из проблем, связанных с серверными фермами, заключается в отсутствии общего кэша — каждый обрабатывающий узел обладает собственной памятью. Эта проблема может быть решена установкой дорогостоящей мультипроцессорной системы с разделяемой памятью, однако существует и более дешевый способ. Он заключается в том, что входной модуль запоминает, на какой узел он посылал запросы конкретных страниц. Последующие запросы тех же страниц он сможет тогда направлять на те же узлы. Таким образом, получается, что каждый узел специализируется по своему набору страниц; и отпадает необходимость хранения одних и тех же файлов в кэшах разных компьютеров. Другая проблема, возникающая при использовании серверных ферм, состоит в том, что TCP-соединение клиента заканчивается на входном модуле, то есть ответ в любом случае должен пройти через входной модуль (рис. 5.7,а). Здесь как входящий запрос (1), так и исходящий ответ (2) проходят через входной модуль. Иногда для обхода этой проблемы применяется хитрость под названием передача TCP. Суть ее в том, что TCP-соединение продлевается до конечного (обрабатывающего) узла, и он может самостоятельно отправить ответ напрямую клиенту (рис. 5.7,б). Эта передача соединения для клиента незаметна
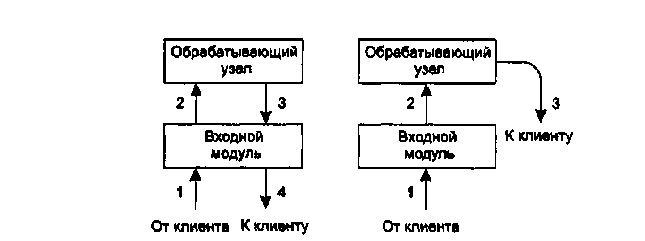
Рисунок 5.7 — Обычный запрос ответный обмен (а);
Обмен запросами и ответами при передаче TCP (б)